Crédit Agricole Technologies et Services
Crédit Agricole Technologies et Services (CA-TS) assure la conception, la fabrication et la maintenance du système d'information bancaire technologique des 39 Caisses régionales du Crédit Agricole

Sommaire
- Introduction
-
Découverte Ansible
-
Initiation méthode agile
-
Déploiement d'archive et tri automatique
- Automatisation web
Introduction
Au cours de mon stage, j'ai été chargé de travailler sur deux projets visant à optimiser et automatiser certaines tâches essentielles pour la squad.
Le premier projet concerne la gestion des archives. La squad gère un volume important d'archives numériques issues du déchargement des bases Oracle. Par souci de temps, la priorité a été donnée à l'extraction des données, et leur organisation a été prévue dans un second temps. Mon rôle a été de mettre en place un processus automatisé permettant d'extraire leur contenu, puis de le classer dans de nouvelles archives en fonction de la date (année et mois d'origine des fichiers). Une fois ce tri effectué, un mécanisme de vérification doit s'assurer que l'opération s'est déroulée sans erreur.
Le second projet porte sur l'automatisation des interactions avec une solution web utilisée par la squad pour effectuer des requêtes dans le but de récupérer des informations financières. Actuellement, cette plateforme ne dispose pas d'API pour automatiser ces actions. Mon objectif a donc été d'améliorer un script Python déjà initié par mon tuteur afin d'automatiser des actions sur le navigateur. Cela inclut la connexion à deux plateformes, la modification automatique des mots de passe sur plusieurs environnements, l'exécution de requêtes simultanées sur ces différents environnements, ainsi que la déconnexion des plateformes.
Ces deux projets ont pour objectif commun d'améliorer l'efficacité des opérations de la squad en réduisant le temps consacré aux tâches répétitives et en minimisant les risques d'erreur.
Découverte Ansible
Mon tuteur m’a d’abord parlé d’Ansible, un outil permettant d’automatiser le déploiement sur des serveurs. L’un de ses avantages est qu’il garantit un résultat identique à chaque exécution, quelle que soit la machine cible. Il m’a ensuite montré comment Ansible est utilisé chez CA-TS, où il est intégré dans un processus CI/CD de manière spécifique. Pour approfondir mes connaissances, j’ai lu plusieurs documentations sur Ansible, notamment le blog de Stephan ROBERT, afin d’apprendre à m’en servir efficacement.
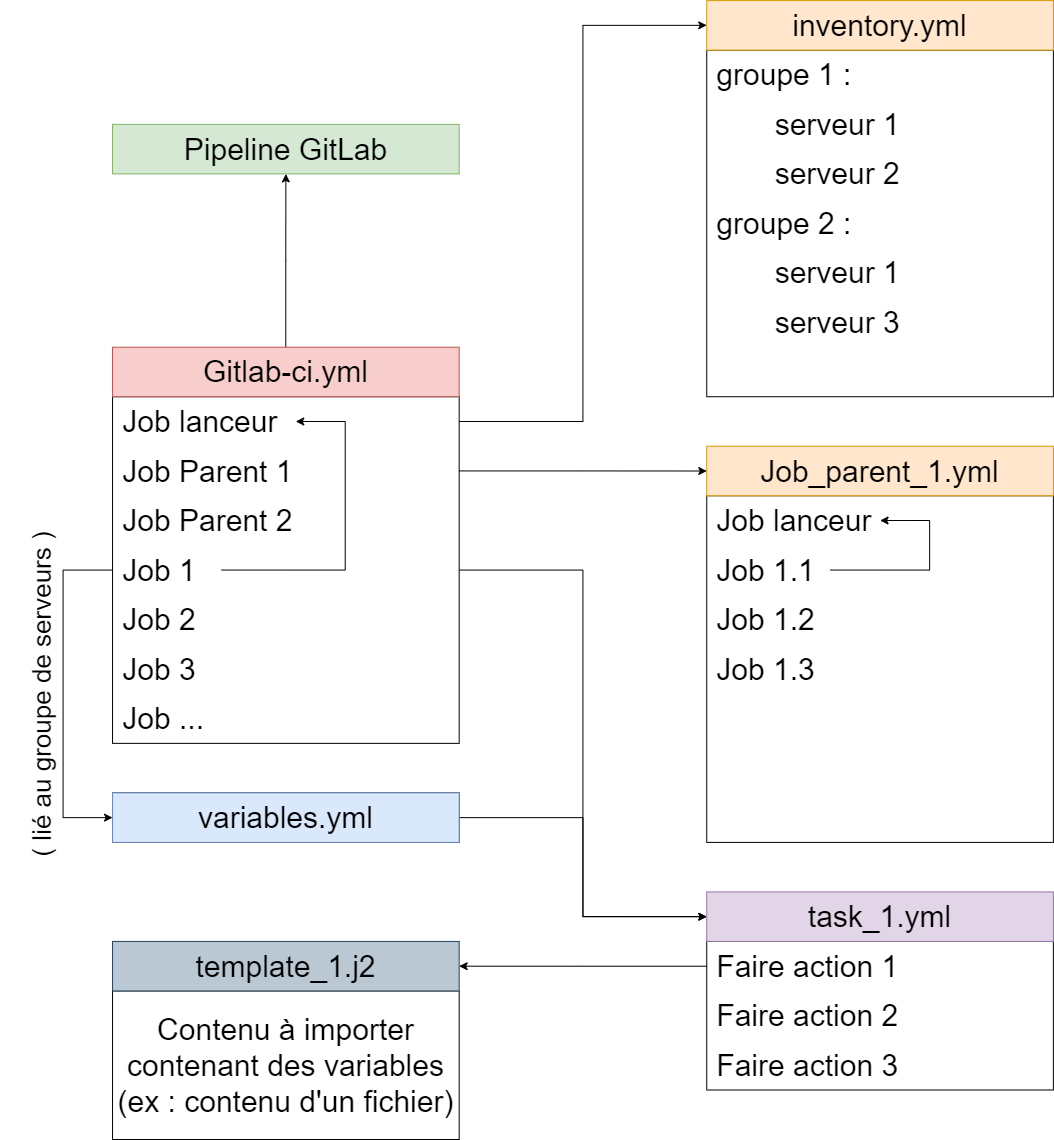
J’ai ensuite mis en pratique mes connaissances en réalisant un projet avec Ansible, en suivant l’architecture CI/CD utilisée chez CA-TS. L’objectif était d’automatiser la gestion d’un fichier sur un serveur en passant par plusieurs étapes. Tout d’abord, Ansible devait créer ce fichier, puis le remplir dynamiquement à l’aide d’un template Jinja2 (.j2), ce qui permettait d’y injecter des variables adaptées à chaque serveur cible. Ensuite, le fichier devait être supprimé afin de tester l’ensemble du processus sur différents serveurs en le rendant paramétrable grâce à l’utilisation de variables Ansible. Pour orchestrer cette automatisation, j’ai dû configurer un fichier gitlab-ci.yml afin de définir les jobs à exécuter dans la pipeline CI/CD. Cela m’a permis de structurer l’exécution des différentes étapes en veillant à ce qu’Ansible soit lancé au bon moment et avec les bonnes variables en fonction du serveur cible. Grâce à cette approche, j’ai pu expérimenter la mise en place d’un workflow CI/CD automatisé et reproductible.
Architecture Ansible CI/CD:
Integration continue:

Déploiement continue:

Initiation méthode agile
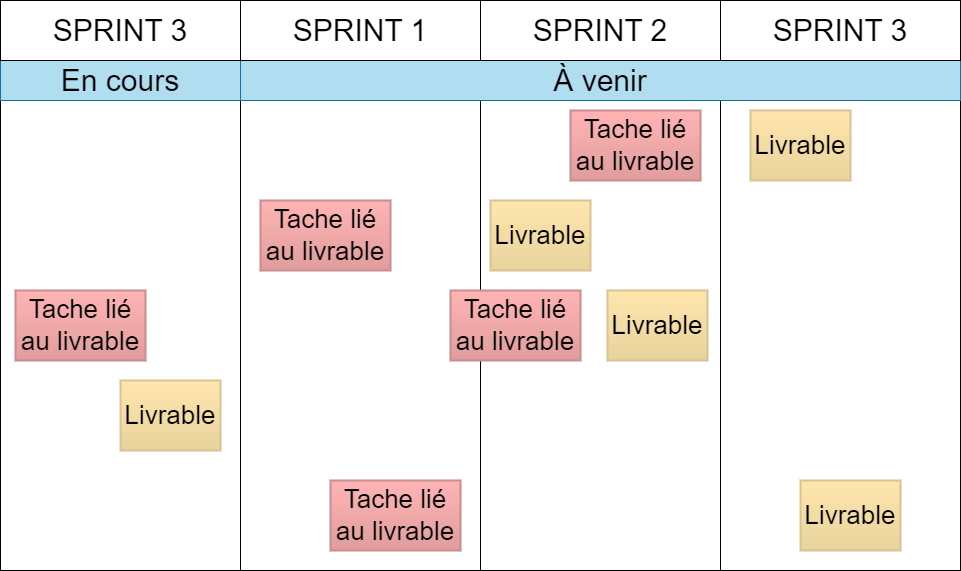
Le Scrum Master de l’équipe m’a présenté, à l’aide d’un diaporama, l’adoption de la méthode Agile chez CA-TS et les raisons du passage du cycle en V à Agile, notamment la nécessité de s’adapter aux évolutions constantes des besoins clients grâce à des feedbacks continus. Il a expliqué le rôle de chaque acteur dans cette approche et détaillé son application au sein de l’équipe que j’ai intégrée, en mettant en avant l’organisation en trimestre de trois sprints, les réunions quotidiennes et l’amélioration de la réactivité et de la satisfaction client.
J’ai activement contribué à l’agilité de l’équipe en partageant l’avancement de mon travail lors des daily meetings, en participant aux points hebdomadaires et en échangeant sur les obstacles rencontrés. J’ai également assisté au PI Planning, un moment clé où l’équipe se réunit pour planifier les projets du prochain trimestre, ainsi qu’à la revue de sprint, qui permet de présenter les réalisations du mois. Cette revue est suivie d’une rétrospective axée sur l’amélioration continue du fonctionnement de l’équipe, en identifiant ce qu’il faut conserver, ajuster/stopper ou introduire pour optimiser la collaboration.
PI planning:
Déploiement d'archive et tri automatique
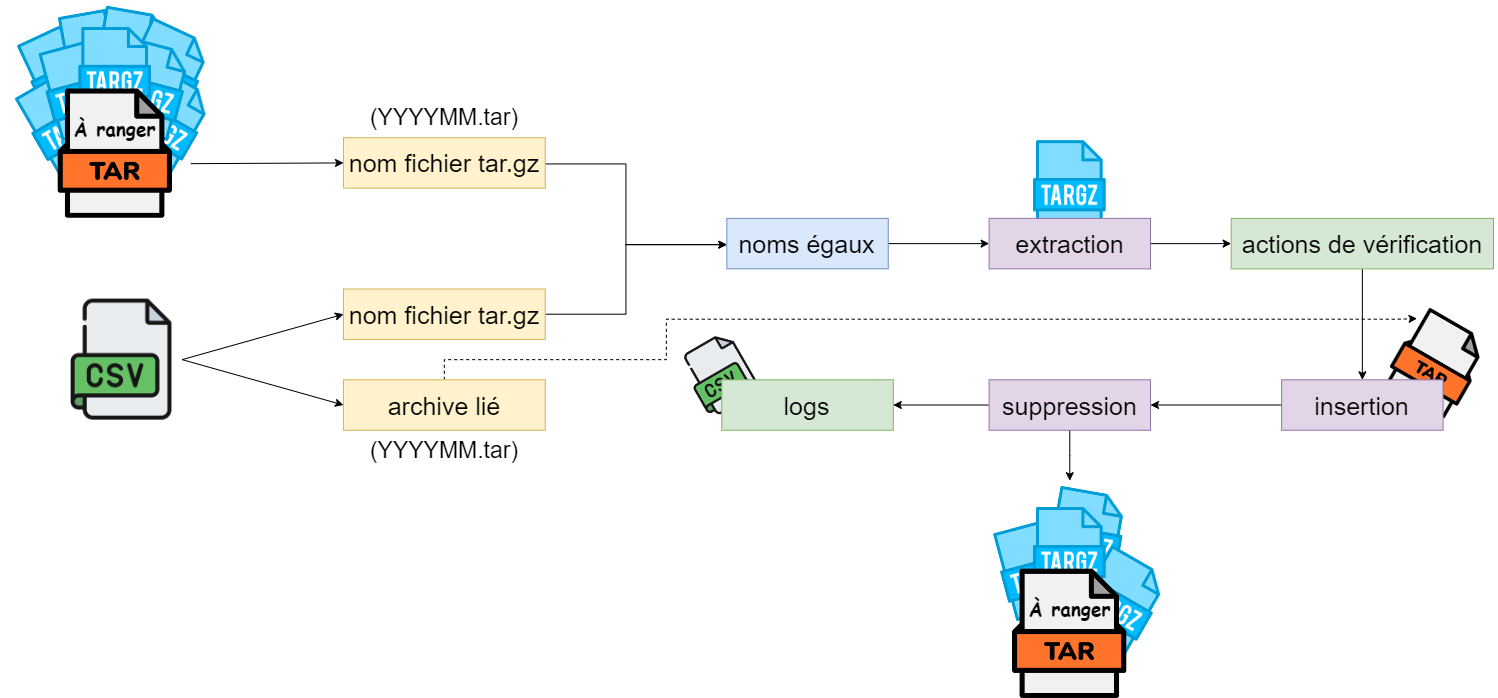
Le projet avait pour objectif d’automatiser le tri et l’organisation d’une archive volumineuse en fonction d’un fichier CSV, précisant comment chaque fichiers de l’archive devait être stockée selon sa date (année et mois). Initialement, ce projet était conçu pour être réalisé avec Ansible, mais en raison des limitations de l’environnement CA-TS, qui empêche l’utilisation de certains modules à des fin de sécurité, j’ai dû développer un script Bash. Ce script permet de vérifier la validité des arguments (fichier CSV, emplacement des archives, dossier de logs, etc.), d'effectuer le tri ou la vérification des archives, et d'enregistrer chaque action dans un fichier CSV pour assurer un suivi. En cas d’erreur, le script retourne un code d’erreur 1 qui signifie qu'il faut consulter les logs.
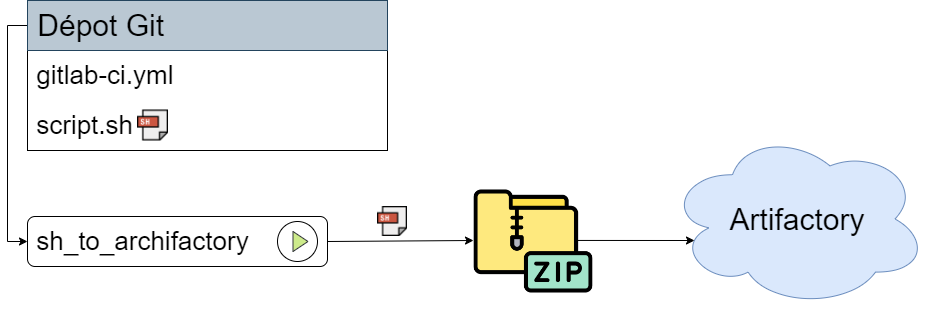
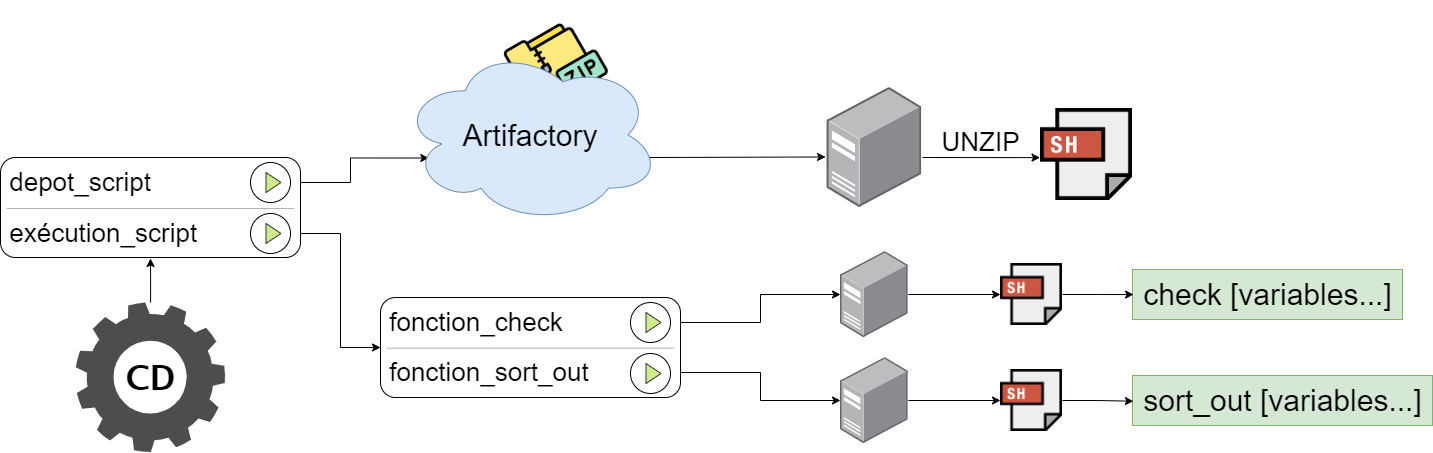
Une fois le script terminé, j’ai pu repasser sur Ansible pour préparer le déploiement automatique. Pour ce faire, j’ai créé un pipeline GitLab CI dans un projet, permettant d’envoyer les scripts Bash (.sh) de mon dépôt vers Artifactory ( serveur de stockage utilisé pour déployer des paquets sur des serveurs avec Ansible ). Dans mon projet de test, j’ai mis en place deux jobs parents dans mon gitlab-ci. Le premier contient un job enfant chargé de déposer un fichier CSV stocké dans Artifactory. Le deuxième permet de déposer mon script stocké dans Artifactory, puis de l’exécuter avec la fonction de vérification ou la fonction de rangement, en utilisant les variables définies pour le serveur concerné dans l’architecture de fichiers Ansible. Actuellement, il reste encore à tester cette implémentation.Pour automatiser le déploiement du script, j’ai mis en place un pipeline GitLab CI qui dépose le script nécessaires sur Artifactory, puis le déploient sur les serveurs souhaiter et l'exécute via Ansible, en fonction des variables définies pour chaque serveur.
Vue simplifiée sort_out:
Envoi dans Artifactory:
Déploiement du script:
Automatisation web
Après l'installation de Conda, qui permet de créer un environnement et d'installer des ressources Python sans être limité par la version de Python installée sur le système, mon tuteur m'a donné un programme Python qu'il a créé. Ce programme permet de se connecter à un progiciel, d'exécuter une requête, puis de se déconnecter, le tout sur plusieurs serveurs simultanément, afin de construire un tableau récapitulatif des résultats d'exécution.
Il a été nécessaire d'ajouter au programme une connexion et une déconnexion à un second progiciel, similaire au premier. Pour cela, les fonctions existantes ont été dupliquées et modifiées en fonction des différences HTML entre les deux sites.
Une fonction de changement de mot de passe sur ce second progiciel a également été développée. Par ailleurs, sur le premier progiciel, une nouvelle fonctionnalité a été implémentée pour permettre l'exécution d'une requête spécifique selon une entrée utilisateur. Ces requêtes renvoient un nombre de lignes variable d'une exécution à l'autre. Ainsi, un tableau récapitulatif indique pour chaque serveur si la requête a été correctement exécutée et informe l'utilisateur de la nécessité de consulter les résultats.
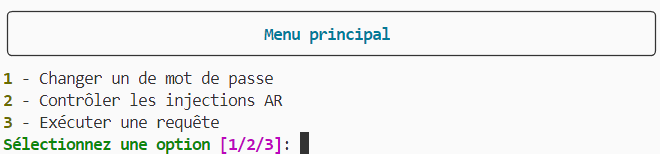
Enfin, un menu a été ajouté, permettant de sélectionner l'action à exécuter.
exemple fonction de connexion:

menu de séléction: